
Learning to Walk in Minutes Using Massively Parallel Deep RL
Robotic Systems Lab: Legged Robotics at ETH Zürich
Published at : 14 Oct 2021
Published at : 14 Oct 2021
26846 views
283
3
We present a training set-up that achieves fast policy generation for real-world robotic tasks by using massive parallelism on a single workstation GPU. The parallel approach allows training policies for flat terrain in under 4 minutes, and in 20 minutes for uneven terrain.
Paper accepted to CoRL 2021.
The corresponding code will be released soon.
Paper: https://arxiv.org/abs/2109.11978
LearningMinutesUsing

Cake-The Distance

Around The Corner - How Differential Steering Works (1937)

Different Sorts

F1 INSIDE TRACK GERMANY 2018

Time Is Precious! Stop Wasting It on Dumb Things - Jordan Peterson Motivation

DIY FIDGET TOYS IDEAS || Satisfying And Relaxing by 123 GO!

Jake Wesley Rogers - Momentary (Official Music Video)

7 Signs Someone Is Trustworthy

Between the Clouds and the Dirt: A Short Film - Gary Vaynerchuk

Ken Wa Maria - Fundamentals

Britain's got talent 2013 Attraction
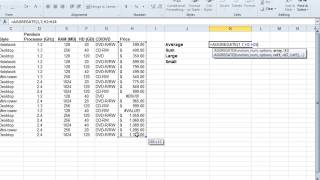
The Aggregate Function in Excel 2010

Introduction to Consumer Choice

7 ALPHA Ways to Make EXTRA MONEY in Your 20s & 30S! (Passive Income Ideas)

Most Common Causes of Death In Ancient Rome and Greece

All Christians Speak Truth to Grow the Body: Ephesians 4:15–16, Part 1

No one ever gave me a SUCCESS PATH to follow in art. I created a SUCCESS PATH for you!

Marshmello & Halsey - Be Kind (Lyrics)

A Lovely day with Windy Spa 05 #24

😍Smart Appliances, Gadgets For Every Home/ Versatile Utensils(Inventions & Ideas)/ MakeupKitchen

Mac Miller - My Favorite Part (feat. Ariana Grande)

Miraa May - Commit

Jeremy Camp, Adrienne Camp - Isn’t The Name

To envisage

Russ - What they want (Official Lyric Video)

Cyn - Drinks (Official Video)

Keep in mind

Having Two Babies After 40 No Longer Excuse for Extra Weight

r/Choosingbeggars Why is Slavery Illegal?!? 😢😭

GW2 - Aphra Behn: "The Disappointment"

An Extremely Realistic Halloween Mask

Taylor Swift - Look What You Made Me Do
![BrxkenBxy - Confirmed (feat. thekidszn) [Official Lyric Video]](https://ytimg.googleusercontent.com/vi/WA-v8_6NIbU/mqdefault.jpg)
BrxkenBxy - Confirmed (feat. thekidszn) [Official Lyric Video]

Queens of the Stone Age - Go With The Flow

The Woman Who Is Constantly Sexually Aroused | Living Differently

How To Be More Mature

US ARMY 82ND AND 101ST AIRBORNE DIVISIONS - WHAT’S THE DIFFERENCE?

Dance with Lea and POP | Guli Guli | A Ram Sam Sam | and more songs for kids

Nikos Vertis - An eisai ena asteri (Official Videoclip)

Significantly Meaning

Its Natascha & Tribal Kush - Position (Official Music Video)

They won't let me leave... Roblox Airplane Story 4!

Nathan Evans - There once was a ship that put to sea (Wellerman) (Lyrics)

Familiarize Yourself

Duvet

ASPECT and TENSE

The Japanese House - Cool Blue

airing in a similar way in the
